



文化は文書という形で蓄積されてきました。
人間ひとりでは、人生を10,000回繰り返しても それらを読破することは不可能でしょう。ネットの普及で、テキストデータは年間2倍のペースで増大しているとも言われます。
しかし人類はコンピュータというツールによって、文書を瞬間的に解析する技術を獲得しました。
本書は、Googleが提供するNgram Viewerの 開発者が、彼らが「カルチャロミクス」と呼称する 文化を定量的に観測する方法,および その意義を紹介しています。
N-gramとは
Google の Ngram Viewerはご存知でしょうか?(https://books.google.com/ngrams)
Ngram Viewerは、Googleブックスの膨大な書籍データから、単語の頻出度を表示してくれるサービスです。
英語,フランス語,ドイツ語,ヘブライ語,イタリア,ロシア語,スペイン語,中国語に対応しています。残念ながら日本語は対応外です。
いくつか試してみましょう。
●「vegan(絶対菜食主義)」
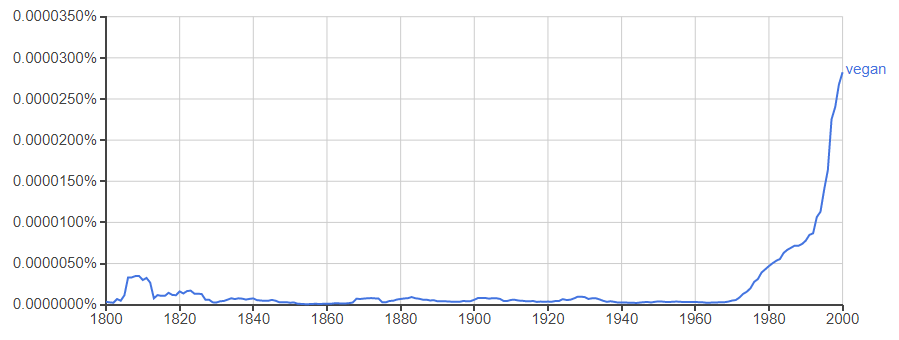
近年、急激に出現頻度を上げています。
●「AI, Artificial Intelligence(人工知能),machine learning(機械学習)」
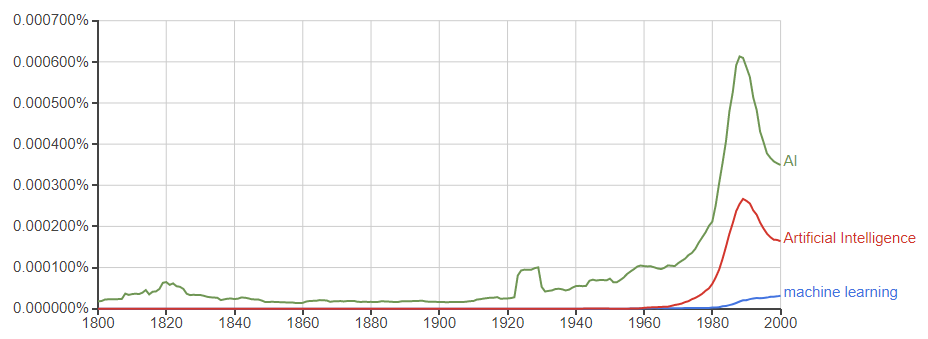
ピークは1990年代、第2次AIブームですね。その後「AIの冬」で、頻度がガクッと落ちています。ここ10年で、また盛り返している?
●著名な科学者
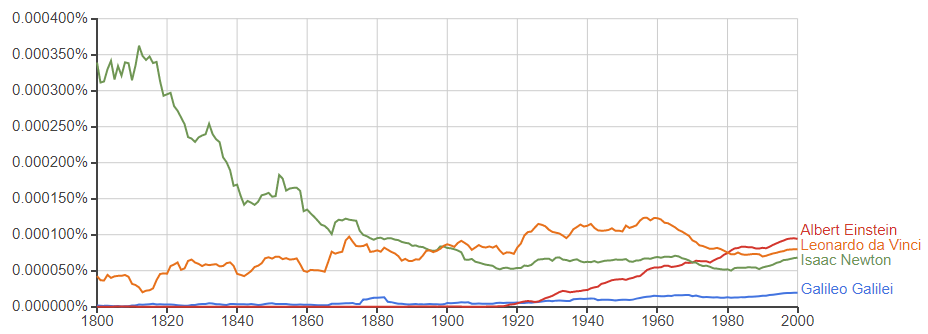
1800年代はNewtonの出現頻度が高いですね。出版物の種類が少なく、相対的に上昇しているのかもしれません。近年では、Einsteinが1位。

一般呼称では結果が変わります。Einstein,Galileoがほぼその人を指すのに対し、Newtonは単位名としての結果が含まれるため逆転しているのでしょう。
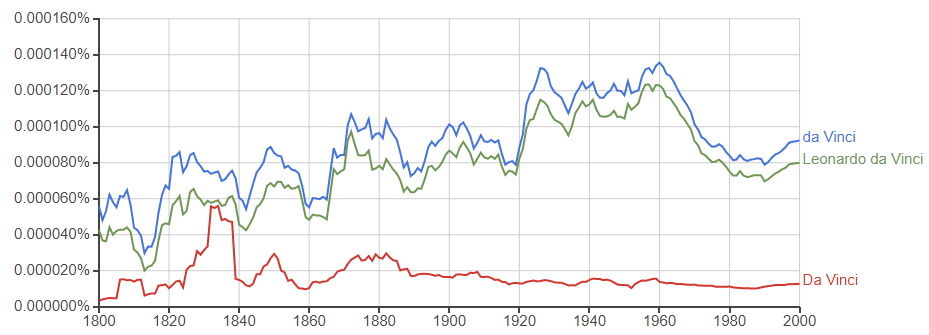
da Vinchは、「Leonald da Vinch」とフルネームで呼称されることがほとんどのようです。
●「Samurai, Ninja」
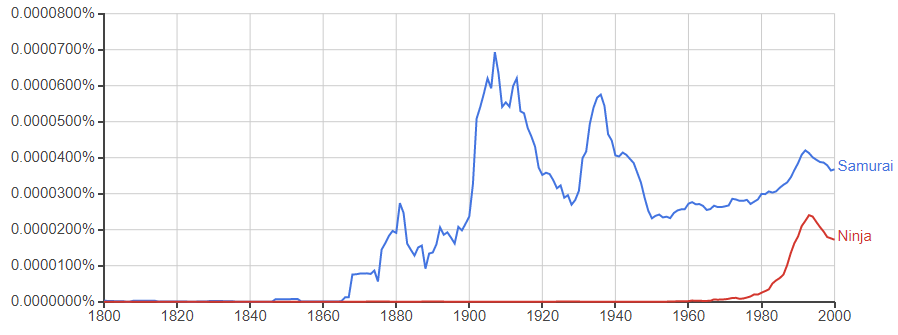
侍は比較的昔から文献に登場していることがわかります。忍者は今でこそ世界的に知られていますが、1980年代のショー・コスギによるNinjaブームまで、ほとんど文献には現れていません。
●「Halley’s Comet(ハレー彗星)」
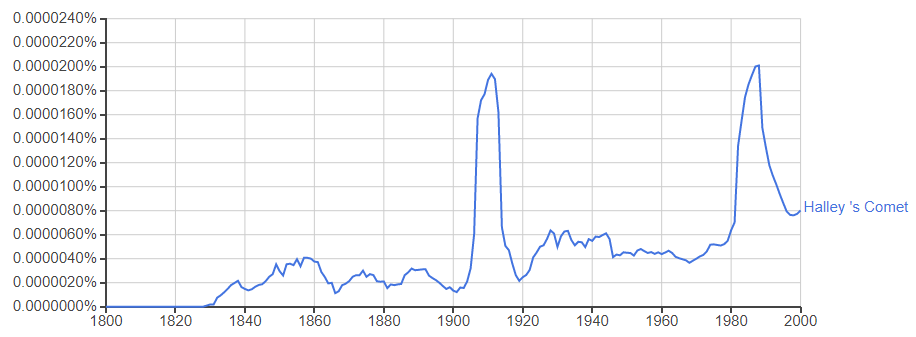
地球に接近する周期で、出現率が急上昇しています。次にやって来るのは2061年!
N-gramとは、文章中の「隣り合ったN文字の塊」を指します。かのクロード・シャノンが考案した言語モデルです。(シャノン末恐ろしい…)
N-gramを用いると、文章中で分節の順が異なっていても単語の種類・頻度を比較できるため、文章の類似度の調査などに使用されます。コピペして、文章中の単語を少し変えたり順番をいじっても、すぐにバレるということですね。
・・・
例を挙げてみましょう。
・毎朝パンを朝食に食べます。
・朝食にパンを毎朝を食べます。
2-gramでの類似度は75% [‘毎朝’, ‘パン’, ‘ンを’, ‘朝食’, ‘食に’, ‘食べ’, ‘べま’, ‘ます’, ‘す。’]
・毎朝パンを朝食に食べます。
・朝ごはんにパンを食べるのが日課です。
2-gramでの類似度は33.3% [‘パン’, ‘ンを’, ‘食べ’, ‘す。’]
・毎朝パンを朝食に食べます。
・私は今ブログを書いています。
2-gramでの類似度は16.7% [‘ます’, ‘す。’]
文の順番を変えただけでは類似度が高く、関連がない文章では類似度が低くなります。
Googleのデジタル図書館
Googleは「世界中のすべての情報の整理」を社是として掲げており、本もその対象です。
こうして生まれたGoogleブックスは、2018年10月のWikipedia情報で、全文表示が100万冊以上,スキャン済みが1200万冊以上となっています。(1,200万冊は2010年のニュースサイトからの引用ですので、2018年現在 世界中のどの図書館の収蔵数より多い?)
それに目をつけたのが、本書の著者 エレツ・エイデンと、ジャン=バティースト・ミシェル。語句の出現頻度から 文化を統計的に評価する研究をしていた彼らにとって、Googleブックスのデータはまさに宝の山です。
しかし、当然立ちはだかるのが著作権の壁。本の全容は閲覧できません。そこで考え出されたのが、N-gramを用いた方法。文脈の要素を削除し、語句だけを参照することによって著作権の壁をクリアしました。
N-gramで見えてくる文化
本書では、N-gramで「文化を定量化した」例がいくつか示されています。
不規則動詞
英語の不規則動詞。はじめて英語に触れる人泣かせの厄介な代物です。何故 -edを付けるだけの規則動詞と、不規則動詞が存在するのでしょう。
その答えは「自然淘汰」にあると、本書では述べられます。
・・・
不規則動詞 sing, ringなどは、インド・ヨーロッパ祖語の変形を受け継いでいます。
sing-sang-sung, ring-rang-rung
その昔、英単語はこれらの不規則動詞が基本系でした。不規則ではなく、昔の基準ではこちらの変形が規則だったのです。
しかし新しい単語が発明されると、従来の不規則動詞の変形では対応できないものが増えてきました。
そこで取り入れられたのが、ドイツ祖語由来の -edを付ける変形。どのような単語にも使用できる利便性から、一気に広がりました。
昔からの不規則動詞と、-edをつける規則動詞。両者が混在した状態が続きます。しかし現在、不規則動詞は動詞全体の3%まで減少しています。
・・・
ジップの法則と呼ばれるべき乗分布が 世界には溢れています。地震の発生頻度と規模,砂粒の大きさと数,収入の分布,友人の数 などは よく知られる例ですね。
べき乗分布は当ブログでも何回か取り上げています。

文章中の単語の出現頻度も、べき乗分布に従います。
本書によると不規則動詞は動詞全体の3%ですが、使用頻度上位10位に入る動詞は すべて不規則動詞だそうです。
つまり、今なお残る不規則動詞は、使用頻度故に その変形を今に残しているのです。
今残っている三〇〇ほどの不規則動詞は、二五〇〇年もの長きにわたって戦ってきた。これらの不規則動詞は単なる例外ではなく、戦いを生き抜いた猛者たちなのである。
ー本文より引用
また本書によると、現在残っている不規則動詞が、将来的に規則動詞に置き換わってしまう時期も使用頻度から予想できるそうです。heave(持ち上げる),shed(発散する),sow(播く),wed(結婚する) などが候補だそう。確かに聞き慣れない単語ばかりです。(weddingはよく聞きますが、「結婚する」ならmarryがよく使われますね。)
Wikipediaの不規則動詞を見てみると、「規則変化もあり」と注意書きされている単語があります。これらが近い将来 規則動詞に置き換わっていくのでしょう。
石が長い時間 水にさらされて角がとれるように、使用頻度によって 単語がどんどん規則化されていくのですね。まさに「自然淘汰」。
日本語では、「ら抜き言葉」がそうでしょうか。ら行が続くと発音しにくいことが ら抜きの一因です。将来的に「ら抜き」の使用頻度が上がると、正式な日本語として使用される将来が見れるでしょう。
客観的な辞書
2018年1月 広辞苑が10年ぶりに改定され、話題となりました。「いらっと」「上から目線」「自撮り」など、最近発明された単語が新掲載されています。
さて、辞書の掲載基準はどうなっているのでしょう。辞書それぞれの特色があるので一概には言えませんが、広辞苑では最終的に編纂者の判断によって決定されるそうです。
N-gramの出現頻度は、人間の判断を排した ある意味 客観的な辞書と言えそうです。言葉は生まれ、やがて廃れます。現在の我々が日常的に使用している語句が、「日本語」という定義ならば、出現頻度は一つの重要な指標でしょう。
もちろん出現頻度だけでは、完璧な辞書とは言えません。専門用語には出現頻度が極端に低いものもあります。識別子が付されて はじめて存在が認知される(老子曰く「名の名とすべきは、常の名にあらず」ですが、)ことから、出現頻度一辺倒では無理がありそうです。
本書によると、全体として英単語は死亡率より出生率が高いらしく、上昇傾向にあるそうです。
世界が狭くなり 新語が広がりやすくなったから。誰でも発信できるようになったから。などと考察されていますが、結局のところ理由はわからないそう。
増えるのは構いませんが、やはり消えゆくのは寂しい気持ちになります。日常的に使用しなくなったとしても、「こういう言葉があった」事実は記録に残していきたいですね。
忘却曲線と学習曲線
痛ましい事件でも、時間の経過とともに忘れ去られます。新しい言葉の普及には、ある程度の時間を要します。
この忘却と学習の期間が年々短くなっていると、本書では述べられています。ネットの出現,情報化社会などが挙げられますが、具体的なメカニズムははっきりとはわからないそうです。上の単語の生成,死滅と同じですね。
個人的な意見を述べると、個々が情報価値をもつようになったことが一因だと思います。マス情報は、個々の情報にすぐに埋没してしまうのではないでしょうか。昔は「珍しい情報」が、今ではすぐに手に入る「お手軽な情報」に変容し、全体の情報量は上がっているものの、情報量同士の差異はなくなっているのかもしれません。
まとめ
本書には他にも、『<名声>の定量化」…近代になるほど名声の期間は短い! 悪名は名声に勝る!』や、『焚書,検閲を検出する』が紹介されています。
N-gram viewerで提示される文化は、「本」という人類が有する ほんの一部分を切り取ったものです。過信はいけないのかもしれませんが、定量化された文化 という切り口が大変おもしろいですね。
文化の定量化ができれば、歴史の法則を抽出し、「統計的に未来を予測する」ことが可能になるのかもしれません。

レヴィ=ストロースの構造主義が、人類の聖杯なのか…!?















